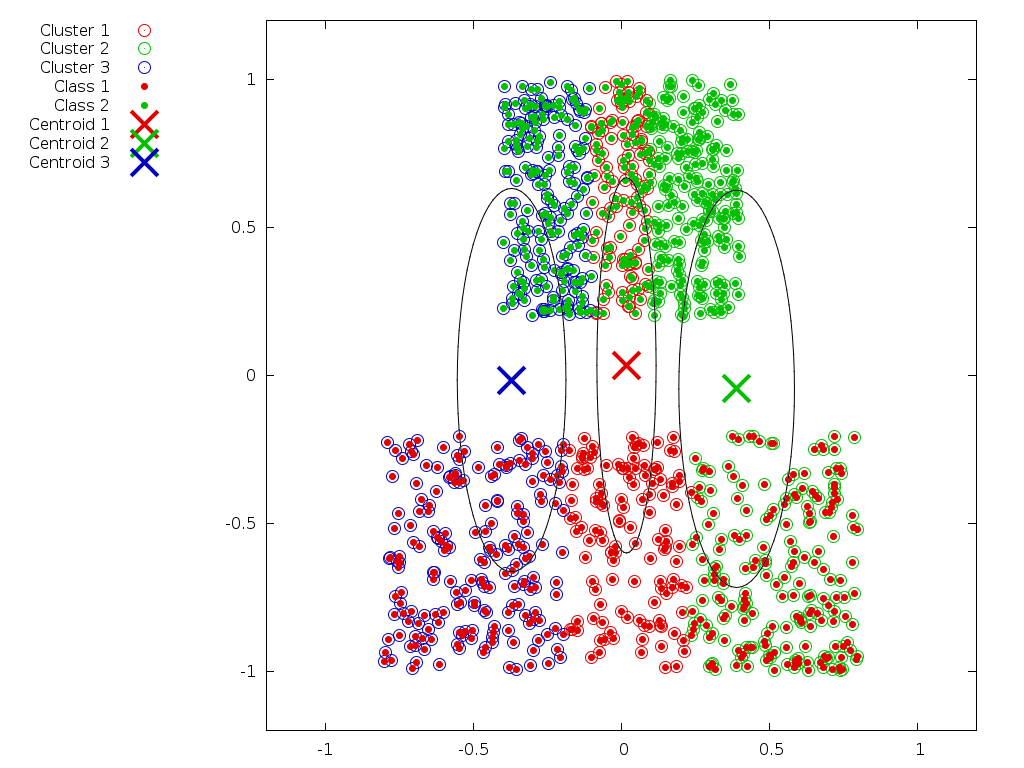
This procedure is a variant of k-means using labelled samples, which enforces in every cluster the same proportion of samples from every class. This ensures that the resulting clusters are totally non-informative about the class, while maximally informative about the signal.
You can get a short report on the method,.
Executing
./test.shwill compile the source, run the algorithm on a 2d toy example, and
produce three graphs (result-standard.png,
result-clueless.png,
and result-clueless-absolute.png)
if you have gnuplot
installed.
{kind=link}
{kind=link}
{kind=link}